# @title
%%capture
print('Install packages, python imports, load the data from Google Drive, create the dataset')
# Install packages
!pip install torchvision;
!pip install segmentation-models-pytorch;
!pip install albumentationsx;
# Imports
from google.colab import drive
import os
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import ToTensor
import torch.optim as optim
import numpy as np
import segmentation_models_pytorch as smp
from segmentation_models_pytorch.losses import DiceLoss, FocalLoss, SoftBCEWithLogitsLoss, SoftCrossEntropyLoss, JaccardLoss, TverskyLoss, LovaszLoss
from segmentation_models_pytorch.metrics import get_stats, iou_score, accuracy, f1_score
import albumentations as A
# Load the data from google drive
drive.mount("/mnt/drive")
images_path = "/mnt/drive/MyDrive/dida/images"
labels_path = "/mnt/drive/MyDrive/dida/labels"
to_predict = "/mnt/drive/MyDrive/dida/to_predict"
# Create the DataSet
class SegmentationDataset(Dataset):
def __init__(self, image_dir, label_dir):
self.image_dir = image_dir
self.label_dir = label_dir
self.common_filenames = sorted(f for f in os.listdir(image_dir) if f in os.listdir(label_dir))
def __len__(self):
return len(self.common_filenames)
def __getitem__(self, idx):
image_path = os.path.join(self.image_dir, self.common_filenames[idx])
label_path = os.path.join(self.label_dir, self.common_filenames[idx])
image_pil = Image.open(image_path)
label_pil = Image.open(label_path)
image_tensor = ToTensor()(image_pil)
label_tensor = ToTensor()(label_pil)
return image_tensor, label_tensor
ds = SegmentationDataset(images_path, labels_path)
train_size = 20
val_size = 4
train_dataset, val_dataset = torch.utils.data.random_split(ds, [train_size, val_size], generator=torch.Generator().manual_seed(42))
train_loader = DataLoader(train_dataset, batch_size=20, shuffle=False)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)Iteration and Experimentation
This notebook contains my process of systematic iteration and experimentation.
The following function encapsulates some of the choices we could make for our model.
It accepts as parameters: - number of epochs: The number of epochs to train for. During testing, I kept this set to 250. - patience: An optional parameter for early stopping if the F1 score does not improve. I created this since in early experiments, the F1 score would start to decrease as the model appeared to overfit. A default value of zero ignores this setting. - model architecture: The model architecture, https://smp.readthedocs.io/en/latest/models.html. - model encoder: The model encoder, https://smp.readthedocs.io/en/latest/encoders.html. - encoder weights: Pretrained encoder weights, https://smp.readthedocs.io/en/latest/encoders.html. - optimizer: The optimizer, https://docs.pytorch.org/docs/stable/optim.html. - learning rate: The learning rate. - loss function: The loss function for the segmentation task, imported from the SMP library https://smp.readthedocs.io/en/latest/losses.html. - verbose (true/false): A setting for whether to print metrics every 10 epochs or not.
It returns the full training / validation records of several loss functions and metrics:
- The losses for the selected loss function. (lower is better)
- The Dice score. (higher is better)
- The Focal score. (lower is better)
- The Binary Cross Entropy score. (lower is better)
- The model accuracy. (higher is better)
- The model F1 score. (higher is better)
# @title
print('Define the train_model function, which takes as input model choices and returns full training / validation records of various metrics')
# Define the device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
def train_model(num_epochs, patience, model_name, encoder_name, encoder_weights, optimizer_type, lr, loss_function_type, verbose=False):
# Define the model
if model_name == "Unet":
model = smp.Unet(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "UnetPlusPlus":
model = smp.UnetPlusPlus(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "FPN":
model = smp.FPN(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "PSPNet":
model = smp.PSPNet(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "DeepLabV3":
model = smp.DeepLabV3(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "DeepLabV3Plus":
model = smp.DeepLabV3Plus(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "Linknet":
model = smp.Linknet(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "MAnet":
model = smp.MAnet(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "PAN":
model = smp.PAN(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "UPerNet":
model = smp.UPerNet(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "Segformer":
model = smp.Segformer(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
elif model_name == "DPT":
model = smp.DPT(encoder_name=encoder_name, encoder_weights=encoder_weights, in_channels=4, classes=1, activation='sigmoid')
else:
raise ValueError(f"Unsupported model name: {model_name}")
# Move the model to the device
model.to(device)
# Define the optimizer
if optimizer_type == "Adadelta":
optimizer = optim.Adadelta(model.parameters(), lr=lr)
elif optimizer_type == "Adafactor":
optimizer = optim.Adafactor(model.parameters(), lr=lr)
elif optimizer_type == 'Adagrad':
optimizer = optim.Adagrad(model.parameters(), lr=lr)
elif optimizer_type == 'Adam':
optimizer = optim.Adam(model.parameters(), lr=lr)
elif optimizer_type == 'AdamW':
optimizer = optim.AdamW(model.parameters(), lr=lr)
elif optimizer_type == 'Adamax':
optimizer = optim.Adamax(model.parameters(), lr=lr)
elif optimizer_type == 'ASGD':
optimizer = optim.ASGD(model.parameters(), lr=lr)
elif optimizer_type == 'NAdam':
optimizer = optim.NAdam(model.parameters(), lr=lr)
elif optimizer_type == 'RAdam':
optimizer = optim.RAdam(model.parameters(), lr=lr)
elif optimizer_type == 'RMSprop':
optimizer = optim.RMSprop(model.parameters(), lr=lr)
elif optimizer_type == 'Rprop':
optimizer = optim.Rprop(model.parameters(), lr=lr)
elif optimizer_type == 'SGD':
optimizer = optim.SGD(model.parameters(), lr=lr)
else:
raise ValueError(f"Unsupported optimizer type: {optimizer_type}")
# Define the loss function
if loss_function_type == 'FocalLoss':
loss_function = FocalLoss(mode="binary")
elif loss_function_type == 'DiceLoss':
loss_function = DiceLoss(mode="binary")
elif loss_function_type == 'LogDiceLoss':
loss_function = DiceLoss(mode="binary", log_loss=True)
elif loss_function_type == 'SoftBCEWithLogitsLoss':
loss_function = SoftBCEWithLogitsLoss()
elif loss_function_type == 'IOULoss':
loss_function = JaccardLoss(mode="binary")
elif loss_function_type == 'TverskyLoss':
loss_function = TverskyLoss(mode="binary")
elif loss_function_type == "LovaszLoss":
loss_function = LovaszLoss(mode="binary")
elif loss_function_type == 'CombinedLoss':
bce_loss = SoftBCEWithLogitsLoss()
log_dice_loss = DiceLoss(mode="binary", log_loss=True)
loss_function = lambda outputs, labels: bce_loss(outputs, labels) + log_dice_loss(outputs, labels)
else:
raise ValueError(f"Unsupported loss function type: {loss_function_type}")
print("-" * 50)
print(f"Training with Model Architecture: {model_name}, Encoder: {encoder_name}, Weight: {encoder_weights}, Optimizer: {optimizer_type}, LR: {lr}, Loss Function: {loss_function_type}")
# Early stopping parameters based on F1
best_val_f1 = float('-inf')
epochs_no_improve = 0
train_losses = []
train_dices = []
train_focals = []
train_bce = []
train_accuracies = []
train_f1_scores = []
val_losses = []
val_dices = []
val_focals = []
val_bce = []
val_accuracies = []
val_f1_scores = []
for epoch in range(num_epochs):
# Set the model to training mode
model.train()
running_loss = 0.0
running_dice = 0.0
running_focal = 0.0
running_bce = 0.0
running_accuracy = 0.0
running_f1 = 0.0
for i, (images, labels) in enumerate(train_loader):
# Move data to the device
images = images.to(device)
labels = labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(images)
# Calculate the loss
loss = loss_function(outputs, labels)
# Calculate other metrics (assuming these are still desired)
# These metrics are independent of the chosen main loss function
batch_dice = 1.0 - DiceLoss(mode="binary")(outputs, labels)
batch_focal = FocalLoss(mode="binary")(outputs, labels)
batch_bce = SoftBCEWithLogitsLoss()(outputs, labels)
labels_long = labels.long()
tp, fp, fn, tn = get_stats(outputs, labels_long, mode="binary", threshold=0.5)
batch_accuracy = accuracy(tp, fp, fn, tn).mean()
batch_f1 = f1_score(tp, fp, fn, tn).mean()
# Backward pass and optimize
loss.backward()
optimizer.step()
# Update running metrics
running_loss += loss.item()
running_focal += batch_focal.item()
running_bce += batch_bce.item()
running_dice += batch_dice.item()
running_accuracy += batch_accuracy.item()
running_f1 += batch_f1.item()
train_losses.append(running_loss / len(train_loader))
train_focals.append(running_focal / len(train_loader))
train_bce.append(running_bce / len(train_loader))
train_dices.append(running_dice / len(train_loader))
train_accuracies.append(running_accuracy / len(train_loader))
train_f1_scores.append(running_f1 / len(train_loader))
# Print metrics
if verbose and (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}] finished. Training Loss: {train_losses[-1]:.4f}, Training Dice: {train_dices[-1]:.4f}, Training Focals: {train_focals[-1]:.4f}, Training BCE: {train_bce[-1]:.4f}, Training Accuracy: {train_accuracies[-1]:.4f}, Training F1: {train_f1_scores[-1]:.4f}')
# Evaluation loop after each epoch
# Set the model to evaluation mode
model.eval()
validation_loss = 0.0
validation_dice = 0.0
validation_focal = 0.0
validation_bce = 0.0
validation_accuracy = 0.0
validation_f1 = 0.0
# Disable gradient calculation for evaluation
with torch.no_grad():
for images, labels in val_loader:
# Move data to the device
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
# Calculate the loss
loss = loss_function(outputs, labels)
# Calculate other metrics
batch_dice = 1.0 - DiceLoss(mode="binary")(outputs, labels)
batch_focal = FocalLoss(mode="binary")(outputs, labels)
batch_bce = SoftBCEWithLogitsLoss()(outputs, labels)
labels_long = labels.long()
tp, fp, fn, tn = get_stats(outputs, labels_long, mode="binary", threshold=0.5)
batch_accuracy = accuracy(tp, fp, fn, tn).mean()
batch_f1 = f1_score(tp, fp, fn, tn).mean()
# Update running metrics
validation_loss += loss.item()
validation_dice += batch_dice.item()
validation_focal += batch_focal.item()
validation_bce += batch_bce.item()
validation_accuracy += batch_accuracy.item()
validation_f1 += batch_f1.item()
average_validation_loss = validation_loss / len(val_loader)
average_validation_dice = validation_dice / len(val_loader)
average_validation_focal = validation_focal / len(val_loader)
average_validation_bce = validation_bce / len(val_loader)
average_validation_accuracy = validation_accuracy / len(val_loader)
average_validation_f1 = validation_f1 / len(val_loader)
val_losses.append(average_validation_loss)
val_dices.append(average_validation_dice)
val_focals.append(average_validation_focal)
val_bce.append(average_validation_bce)
val_accuracies.append(average_validation_accuracy)
val_f1_scores.append(average_validation_f1)
# Print metrics
if verbose and (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}] finished. Validation Loss: {val_losses[-1]:.4f}, Validation Dice: {val_dices[-1]:.4f}, Validation Focal: {val_focals[-1]:.4f}, Validation BCE: {val_bce[-1]:.4f}, Validation Accuracy: {val_accuracies[-1]:.4f}, Validation F1: {val_f1_scores[-1]:.4f}')
if patience != 0:
# Early stopping check
if average_validation_f1 > best_val_f1:
best_val_f1 = average_validation_f1
epochs_no_improve = 0
else:
epochs_no_improve += 1
if epochs_no_improve == patience:
print(f'Early stopping after {epoch+1} epochs.')
break # Stop training loop
print('Finished Training')
print(f'Training Loss: {train_losses[-1]:.4f}, Training Dice: {train_dices[-1]:.4f}, Training Focals: {train_focals[-1]:.4f}, Training BCE: {train_bce[-1]:.4f}, Training Accuracy: {train_accuracies[-1]:.4f}, Training F1: {train_f1_scores[-1]:.4f}')
print(f'Validation Loss: {val_losses[-1]:.4f}, Validation Dice: {val_dices[-1]:.4f}, Validation Focals: {val_focals[-1]:.4f}, Validation BCE: {val_bce[-1]:.4f}, Validation Accuracy: {val_accuracies[-1]:.4f}, Validation F1: {val_f1_scores[-1]:.4f}')
# Return the trained model and metrics
return model, train_losses, train_dices, train_focals, train_bce, train_accuracies, train_f1_scores, val_losses, val_dices, val_focals, val_bce, val_accuracies, val_f1_scoresDefine the train_model function, which takes as input model choices and returns full training / validation records of various metrics
Using device: cudaI define a helper function for plotting the various metrics. It takes as input a user selection of the model training data. In doing so, the plots for different choices can be visually inspected and analyzed.
# @title
print('Define the plot selected function, for plotting metrics')
def plot_selected(results, selected, plot_loss=True):
if plot_loss:
metrics = [['train_losses', 'val_losses'], ['train_dices', 'val_dices'], ['train_focals', 'val_focals'], ['train_bce', 'val_bce'], ['train_accuracies', 'val_accuracies'], ['train_f1_scores', 'val_f1_scores']]
else:
metrics = [['train_dices', 'val_dices'], ['train_focals', 'val_focals'], ['train_bce', 'val_bce'], ['train_accuracies', 'val_accuracies'], ['train_f1_scores', 'val_f1_scores']]
for train_val_pair in metrics:
plt.figure(figsize=(8, 4))
for metric in train_val_pair:
for combination in selected:
plt.plot(results[combination][metric], label=f'{combination} - {metric.replace("_", " ").title()}')
plt.xlabel("epoch")
plt.ylabel("metric value")
plt.title("metric")
plt.legend()
plt.grid(True)
plt.show()Define the plot selected function, for plotting metrics1 Encoder and Weights
I begin by training and testing a selection of model encoders and pretrained weights.
While testing, I was able to plot the results interactively. This was very helpful for being able to directly compare combinations. However it would not render on GitHub, so I had to replace the interactive plots with static plots.
# @title
encoder_weight_results = {}
encoder_weight_pairs = [
("resnet34", "imagenet"),
("resnet152", "imagenet"),
("resnext101_32x8d", "imagenet"),
("dpn107", "imagenet+5k"),
("dpn131", "imagenet"),
("vgg19", "imagenet"),
("vgg19_bn", "imagenet"),
("senet154", "imagenet"),
("inceptionresnetv2", "imagenet"),
("inceptionresnetv2", "imagenet+background"),
("efficientnet-b7", "imagenet"),
("efficientnet-b7", "advprop"),
("timm-efficientnet-b8", "imagenet"),
("timm-efficientnet-b8", "advprop"),
("mit_b5", "imagenet"),
]
for encoder, weight in encoder_weight_pairs:
model, train_losses, train_dices, train_focals, train_bce, train_accuracies, train_f1_scores, val_losses, val_dices, val_focals, val_bce, val_accuracies, val_f1_scores = train_model(
num_epochs=200,
patience=0,
model_name="Unet",
encoder_name=encoder,
encoder_weights=weight,
optimizer_type="Adam",
lr=1e-4,
loss_function_type="DiceLoss"
)
encoder_weight_results[f'{encoder}_{weight}'] = {
'train_losses': train_losses,
'train_dices': train_dices,
'train_focals': train_focals,
'train_bce': train_bce,
'train_accuracies': train_accuracies,
'train_f1_scores': train_f1_scores,
'val_losses': val_losses,
'val_dices': val_dices,
'val_focals': val_focals,
'val_bce': val_bce,
'val_accuracies': val_accuracies,
'val_f1_scores': val_f1_scores
}/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(--------------------------------------------------
Training with Model Architecture: Unet, Encoder: resnet34, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6955, Training Dice: 0.3045, Training Focals: 0.1759, Training BCE: 0.6785, Training Accuracy: 0.9718, Training F1: 0.8942
Validation Loss: 0.7543, Validation Dice: 0.2457, Validation Focals: 0.1970, Validation BCE: 0.7204, Validation Accuracy: 0.9082, Validation F1: 0.5268--------------------------------------------------
Training with Model Architecture: Unet, Encoder: resnet152, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6950, Training Dice: 0.3050, Training Focals: 0.1743, Training BCE: 0.6761, Training Accuracy: 0.9732, Training F1: 0.8990
Validation Loss: 0.7408, Validation Dice: 0.2592, Validation Focals: 0.1945, Validation BCE: 0.7126, Validation Accuracy: 0.9285, Validation F1: 0.6610--------------------------------------------------
Training with Model Architecture: Unet, Encoder: resnext101_32x8d, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7068, Training Dice: 0.2932, Training Focals: 0.2155, Training BCE: 0.7369, Training Accuracy: 0.9675, Training F1: 0.8799
Validation Loss: 0.7584, Validation Dice: 0.2416, Validation Focals: 0.2318, Validation BCE: 0.7716, Validation Accuracy: 0.9168, Validation F1: 0.5498--------------------------------------------------
Training with Model Architecture: Unet, Encoder: dpn107, Weight: imagenet+5k, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6966, Training Dice: 0.3034, Training Focals: 0.1781, Training BCE: 0.6819, Training Accuracy: 0.9704, Training F1: 0.8897
Validation Loss: 0.7607, Validation Dice: 0.2393, Validation Focals: 0.1988, Validation BCE: 0.7256, Validation Accuracy: 0.9063, Validation F1: 0.4435--------------------------------------------------
Training with Model Architecture: Unet, Encoder: dpn131, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6966, Training Dice: 0.3034, Training Focals: 0.1785, Training BCE: 0.6827, Training Accuracy: 0.9728, Training F1: 0.8978
Validation Loss: 0.7441, Validation Dice: 0.2559, Validation Focals: 0.1956, Validation BCE: 0.7166, Validation Accuracy: 0.9396, Validation F1: 0.6946--------------------------------------------------
Training with Model Architecture: Unet, Encoder: vgg19, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6936, Training Dice: 0.3064, Training Focals: 0.1673, Training BCE: 0.6654, Training Accuracy: 0.9747, Training F1: 0.9040
Validation Loss: 0.7480, Validation Dice: 0.2520, Validation Focals: 0.1881, Validation BCE: 0.7058, Validation Accuracy: 0.9258, Validation F1: 0.6197--------------------------------------------------
Training with Model Architecture: Unet, Encoder: vgg19_bn, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6959, Training Dice: 0.3041, Training Focals: 0.1763, Training BCE: 0.6794, Training Accuracy: 0.9733, Training F1: 0.8995
Validation Loss: 0.7772, Validation Dice: 0.2228, Validation Focals: 0.1917, Validation BCE: 0.7211, Validation Accuracy: 0.8956, Validation F1: 0.1318--------------------------------------------------
Training with Model Architecture: Unet, Encoder: senet154, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7006, Training Dice: 0.2994, Training Focals: 0.1912, Training BCE: 0.7018, Training Accuracy: 0.9701, Training F1: 0.8882
Validation Loss: 0.7377, Validation Dice: 0.2623, Validation Focals: 0.2110, Validation BCE: 0.7362, Validation Accuracy: 0.9481, Validation F1: 0.7714--------------------------------------------------
Training with Model Architecture: Unet, Encoder: inceptionresnetv2, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7029, Training Dice: 0.2971, Training Focals: 0.2004, Training BCE: 0.7153, Training Accuracy: 0.9671, Training F1: 0.8788
Validation Loss: 0.7489, Validation Dice: 0.2511, Validation Focals: 0.2295, Validation BCE: 0.7631, Validation Accuracy: 0.9054, Validation F1: 0.5996--------------------------------------------------
Training with Model Architecture: Unet, Encoder: inceptionresnetv2, Weight: imagenet+background, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7008, Training Dice: 0.2992, Training Focals: 0.1924, Training BCE: 0.7036, Training Accuracy: 0.9680, Training F1: 0.8811
Validation Loss: 0.7490, Validation Dice: 0.2510, Validation Focals: 0.2181, Validation BCE: 0.7486, Validation Accuracy: 0.9117, Validation F1: 0.5998--------------------------------------------------
Training with Model Architecture: Unet, Encoder: efficientnet-b7, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7019, Training Dice: 0.2981, Training Focals: 0.1979, Training BCE: 0.7108, Training Accuracy: 0.9623, Training F1: 0.8645
Validation Loss: 0.7321, Validation Dice: 0.2679, Validation Focals: 0.2465, Validation BCE: 0.7750, Validation Accuracy: 0.8742, Validation F1: 0.6238--------------------------------------------------
Training with Model Architecture: Unet, Encoder: efficientnet-b7, Weight: advprop, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7013, Training Dice: 0.2987, Training Focals: 0.1918, Training BCE: 0.7024, Training Accuracy: 0.9616, Training F1: 0.8614
Validation Loss: 0.7303, Validation Dice: 0.2697, Validation Focals: 0.2169, Validation BCE: 0.7413, Validation Accuracy: 0.9415, Validation F1: 0.7770--------------------------------------------------
Training with Model Architecture: Unet, Encoder: timm-efficientnet-b8, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6988, Training Dice: 0.3012, Training Focals: 0.1860, Training BCE: 0.6932, Training Accuracy: 0.9626, Training F1: 0.8643
Validation Loss: 0.7283, Validation Dice: 0.2717, Validation Focals: 0.1969, Validation BCE: 0.7130, Validation Accuracy: 0.9500, Validation F1: 0.7921--------------------------------------------------
Training with Model Architecture: Unet, Encoder: timm-efficientnet-b8, Weight: advprop, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7072, Training Dice: 0.2928, Training Focals: 0.2167, Training BCE: 0.7382, Training Accuracy: 0.9542, Training F1: 0.8390
Validation Loss: 0.7352, Validation Dice: 0.2648, Validation Focals: 0.2255, Validation BCE: 0.7556, Validation Accuracy: 0.9570, Validation F1: 0.8187--------------------------------------------------
Training with Model Architecture: Unet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6974, Training Dice: 0.3026, Training Focals: 0.1785, Training BCE: 0.6825, Training Accuracy: 0.9683, Training F1: 0.8828
Validation Loss: 0.7263, Validation Dice: 0.2737, Validation Focals: 0.1870, Validation BCE: 0.6982, Validation Accuracy: 0.9565, Validation F1: 0.8126plot_selected(encoder_weight_results, ['resnet34_imagenet', 'senet154_imagenet', 'efficientnet-b7_advprop', 'timm-efficientnet-b8_advprop', 'mit_b5_imagenet'])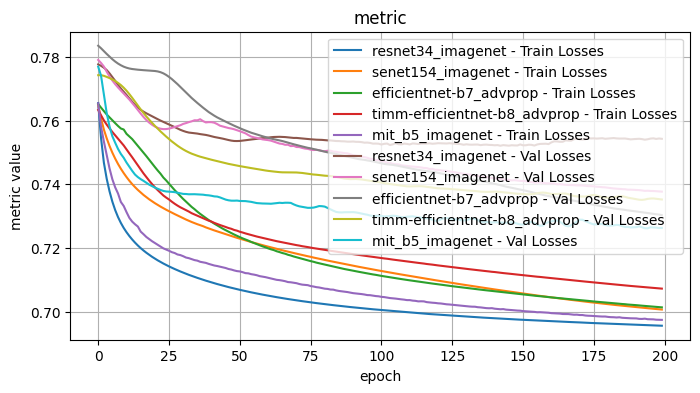
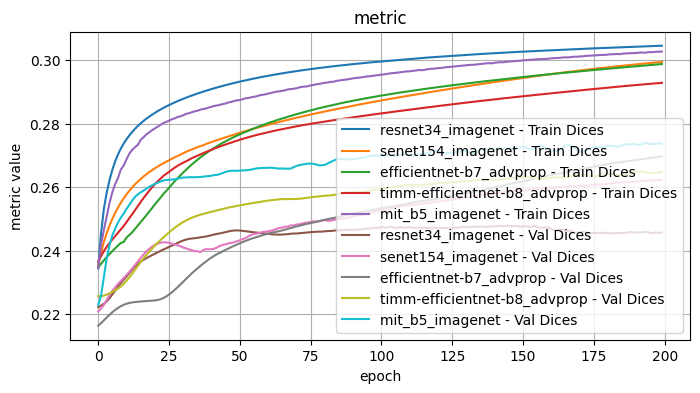
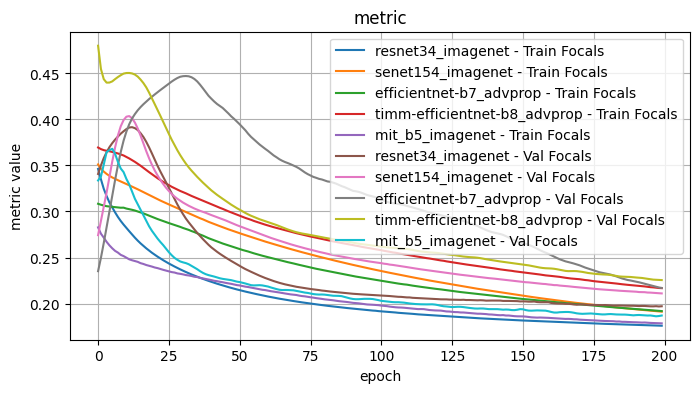
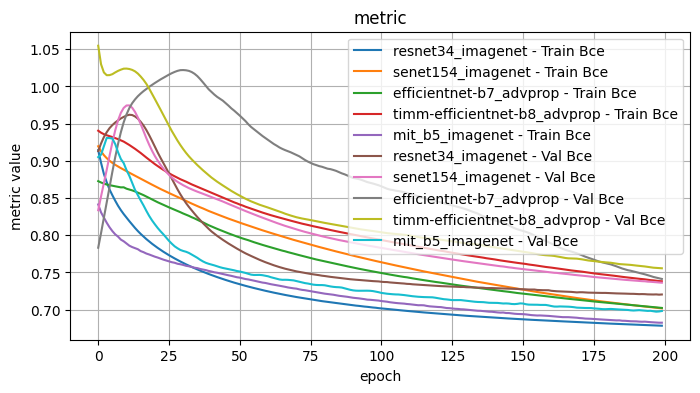
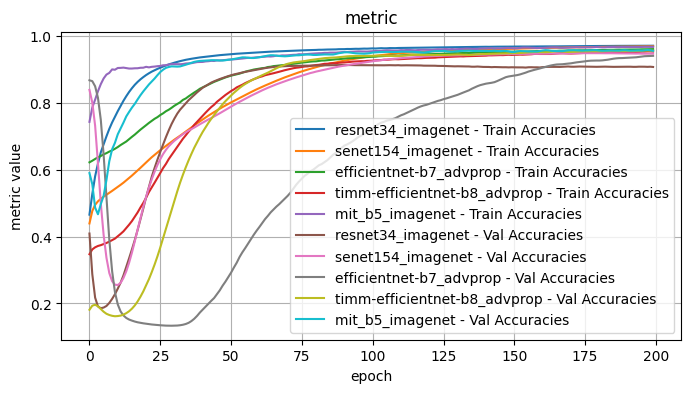
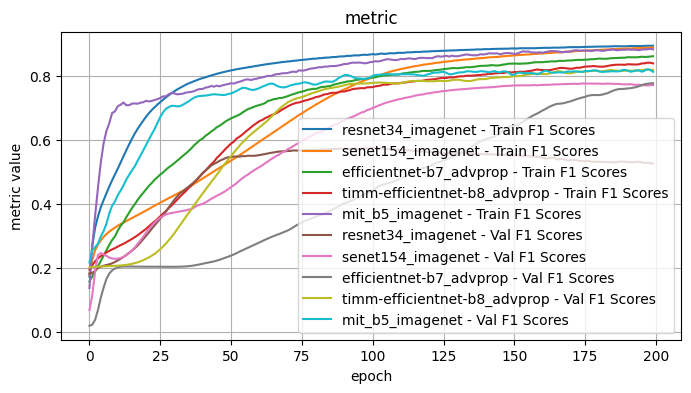
1.1 Conclusions - Model Encoder and Weights
I tested the model encoder and encoder weight pairs with the following fixed choices: Architecture: Unet, Optimizer: Adam, LR: 1e-4, Loss Function: Dice Loss
From inspection, the best performing model encoder / weights pairs were: - senet154 / imagenet - good results initially but surpassed with further training by other encoder/weight pairs - efficientnet-b7 / advprop - a slower initial curve than the pair efficientnet-b7 / imagenet, but surpassed with enough epochs. Performed worse initially for accuracy and F1 scores. - timm_efficientnet-b8 / advprop - some of the best results but with a curve that slows, possible with further epochs would be surpassed by efficientnet-b7 / advprop - mit_b5 - performed well across the board, but surpassed at later epochs. Of particular note, the training and validation scores stayed consistently close.
Further observe: - resnet34 / imagenet, resnet152 / imagenet, resnest101_32x8d / imagenet - The validation scores for multiple metrics decreases with further epochs, suggestive of overfitting
The two best performers appeared to be timm_ifficientnet-b8 / advprop and mit_b5 / imagenet. From the first pass, mit_b5 was the most consistent baseline, so I will use that to test the other model choices and perhaps revisit after further testing.
2 Model Architecture
# @title
model_architecture_results = {}
model_architectures = ['Unet', 'FPN', 'PSPNet', 'DeepLabV3', 'DeepLabV3Plus', 'MAnet', 'PAN', 'UPerNet', 'Segformer']
# incompatible with mit_b5: UnetPlusPlus, Linknet, DPT
for model_architecture in model_architectures:
model, train_losses, train_dices, train_focals, train_bce, train_accuracies, train_f1_scores, val_losses, val_dices, val_focals, val_bce, val_accuracies, val_f1_scores = train_model(
num_epochs=200,
patience=0,
model_name=model_architecture,
encoder_name="mit_b5",
encoder_weights="imagenet",
optimizer_type="Adam",
lr=1e-4,
loss_function_type="DiceLoss"
)
model_architecture_results[model_architecture] = {
'train_losses': train_losses,
'train_dices': train_dices,
'train_focals': train_focals,
'train_bce': train_bce,
'train_accuracies': train_accuracies,
'train_f1_scores': train_f1_scores,
'val_losses': val_losses,
'val_dices': val_dices,
'val_focals': val_focals,
'val_bce': val_bce,
'val_accuracies': val_accuracies,
'val_f1_scores': val_f1_scores
}--------------------------------------------------
Training with Model Architecture: Unet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6974, Training Dice: 0.3026, Training Focals: 0.1814, Training BCE: 0.6866, Training Accuracy: 0.9669, Training F1: 0.8792
Validation Loss: 0.7302, Validation Dice: 0.2698, Validation Focals: 0.1922, Validation BCE: 0.7064, Validation Accuracy: 0.9475, Validation F1: 0.7758
--------------------------------------------------
Training with Model Architecture: FPN, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6889, Training Dice: 0.3111, Training Focals: 0.1584, Training BCE: 0.6488, Training Accuracy: 0.9661, Training F1: 0.8766
Validation Loss: 0.7147, Validation Dice: 0.2853, Validation Focals: 0.1690, Validation BCE: 0.6655, Validation Accuracy: 0.9505, Validation F1: 0.8009
--------------------------------------------------
Training with Model Architecture: PSPNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6903, Training Dice: 0.3097, Training Focals: 0.1622, Training BCE: 0.6541, Training Accuracy: 0.9581, Training F1: 0.8518
Validation Loss: 0.7244, Validation Dice: 0.2756, Validation Focals: 0.1734, Validation BCE: 0.6744, Validation Accuracy: 0.9365, Validation F1: 0.7348
--------------------------------------------------
Training with Model Architecture: DeepLabV3, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6954, Training Dice: 0.3046, Training Focals: 0.1771, Training BCE: 0.6774, Training Accuracy: 0.9506, Training F1: 0.8295
Validation Loss: 0.7187, Validation Dice: 0.2813, Validation Focals: 0.1922, Validation BCE: 0.6988, Validation Accuracy: 0.9271, Validation F1: 0.7419
--------------------------------------------------
Training with Model Architecture: DeepLabV3Plus, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6947, Training Dice: 0.3053, Training Focals: 0.1754, Training BCE: 0.6740, Training Accuracy: 0.9466, Training F1: 0.8182
Validation Loss: 0.7239, Validation Dice: 0.2761, Validation Focals: 0.1828, Validation BCE: 0.6891, Validation Accuracy: 0.9365, Validation F1: 0.7556
--------------------------------------------------
Training with Model Architecture: MAnet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7019, Training Dice: 0.2981, Training Focals: 0.1966, Training BCE: 0.7095, Training Accuracy: 0.9647, Training F1: 0.8722
Validation Loss: 0.7424, Validation Dice: 0.2576, Validation Focals: 0.2075, Validation BCE: 0.7323, Validation Accuracy: 0.9356, Validation F1: 0.7065
--------------------------------------------------
Training with Model Architecture: PAN, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6902, Training Dice: 0.3098, Training Focals: 0.1607, Training BCE: 0.6524, Training Accuracy: 0.9623, Training F1: 0.8636
Validation Loss: 0.7183, Validation Dice: 0.2817, Validation Focals: 0.1748, Validation BCE: 0.6755, Validation Accuracy: 0.9432, Validation F1: 0.7765
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6892, Training Dice: 0.3108, Training Focals: 0.1585, Training BCE: 0.6496, Training Accuracy: 0.9688, Training F1: 0.8859
Validation Loss: 0.7139, Validation Dice: 0.2861, Validation Focals: 0.1654, Validation BCE: 0.6626, Validation Accuracy: 0.9644, Validation F1: 0.8543
--------------------------------------------------
Training with Model Architecture: Segformer, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6897, Training Dice: 0.3103, Training Focals: 0.1600, Training BCE: 0.6515, Training Accuracy: 0.9661, Training F1: 0.8770
Validation Loss: 0.7165, Validation Dice: 0.2835, Validation Focals: 0.1704, Validation BCE: 0.6687, Validation Accuracy: 0.9495, Validation F1: 0.7984plot_selected(model_architecture_results, ['Unet', 'FPN', 'UPerNet', 'Segformer'])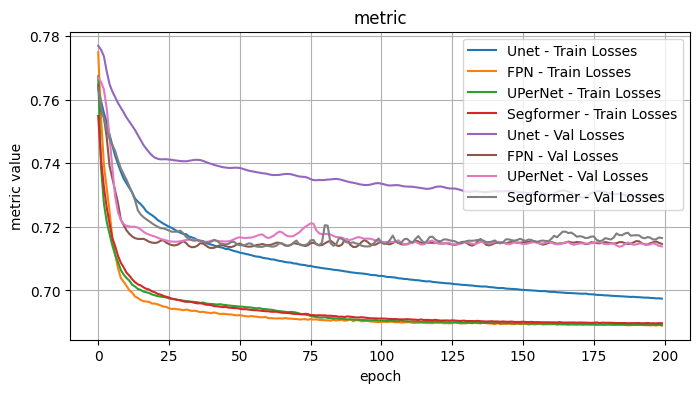
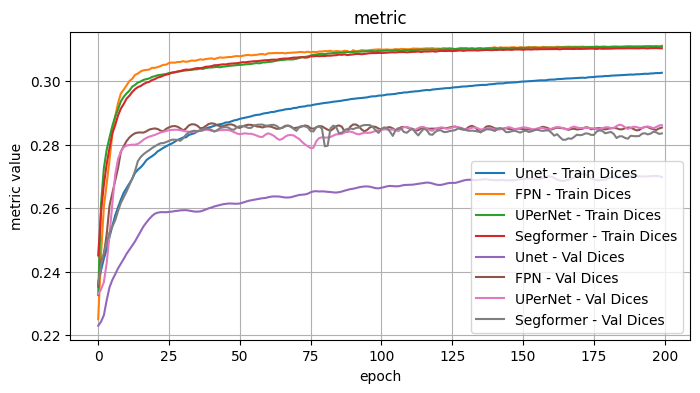
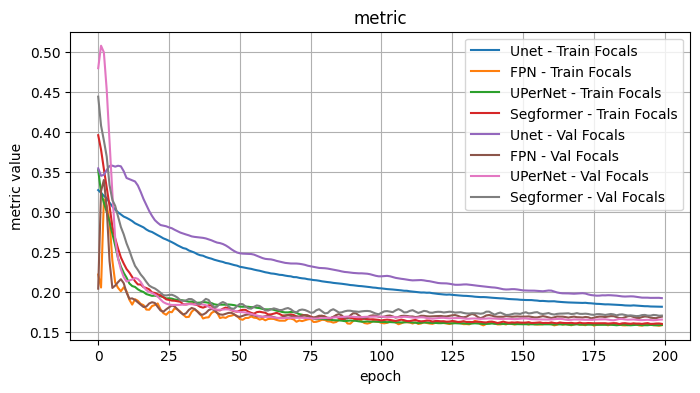
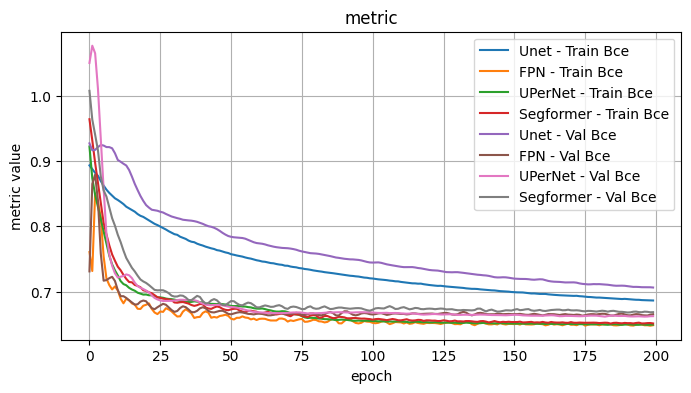
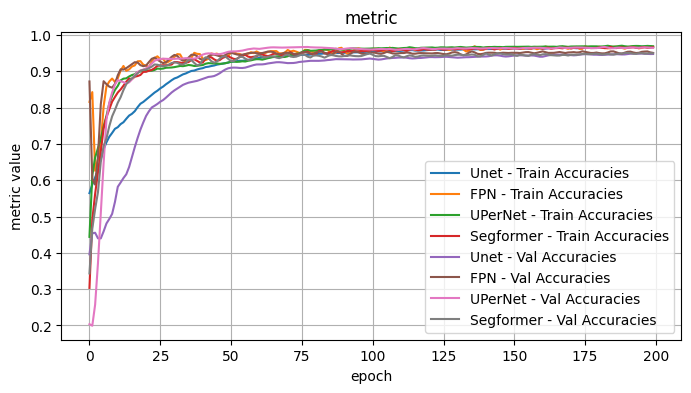
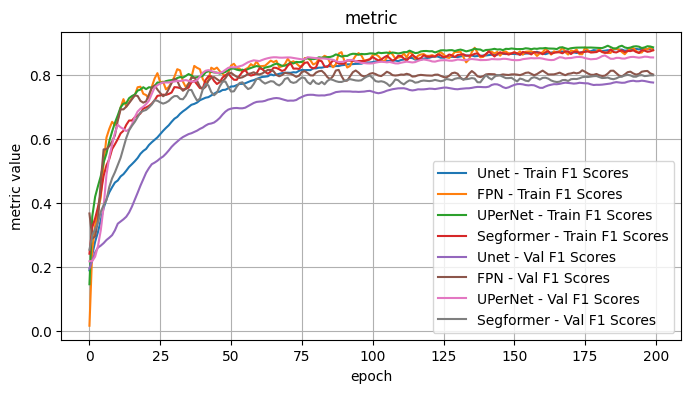
2.1 Conclusion - Model Architecture
I tested the model architecture with the following fixed choices: Model encoder / weights: mit_b5 / imagenet, Optimizer: Adam, LR: 1e-4, Loss Function: Dice Loss
I observe: - The best performers were FPN (although a bit noisy), UPerNet, Segformer - DeepLabV3 outperformed DeepLabV3Plus slightly.
Overall best appears to be UPerNet. In particular, for the given choices the curves were generally smoother with less variance.
3 Optimizers
# @title
optimizer_results = {}
optimizers = ['Adadelta', 'Adafactor', 'Adagrad', 'Adam', 'AdamW', 'Adamax', 'ASGD', 'NAdam', 'RAdam', 'RMSprop', 'Rprop', 'SGD']
for optimizer_type in optimizers:
model, train_losses, train_dices, train_focals, train_bce, train_accuracies, train_f1_scores, val_losses, val_dices, val_focals, val_bce, val_accuracies, val_f1_scores = train_model(
num_epochs=200,
patience=0,
model_name="UPerNet",
encoder_name="mit_b5",
encoder_weights="imagenet",
optimizer_type=optimizer_type,
lr=1e-4,
loss_function_type="DiceLoss"
)
optimizer_results[optimizer_type] = {
'train_losses': train_losses,
'train_dices': train_dices,
'train_focals': train_focals,
'train_bce': train_bce,
'train_accuracies': train_accuracies,
'train_f1_scores': train_f1_scores,
'val_losses': val_losses,
'val_dices': val_dices,
'val_focals': val_focals,
'val_bce': val_bce,
'val_accuracies': val_accuracies,
'val_f1_scores': val_f1_scores
}--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adadelta, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7653, Training Dice: 0.2347, Training Focals: 0.2848, Training BCE: 0.8435, Training Accuracy: 0.7280, Training F1: 0.1400
Validation Loss: 0.7792, Validation Dice: 0.2208, Validation Focals: 0.2899, Validation BCE: 0.8510, Validation Accuracy: 0.7151, Validation F1: 0.1214
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adafactor, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6994, Training Dice: 0.3006, Training Focals: 0.1966, Training BCE: 0.6987, Training Accuracy: 0.9027, Training F1: 0.7654
Validation Loss: 0.7269, Validation Dice: 0.2731, Validation Focals: 0.2074, Validation BCE: 0.7182, Validation Accuracy: 0.8824, Validation F1: 0.6232
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adagrad, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6944, Training Dice: 0.3056, Training Focals: 0.1773, Training BCE: 0.6740, Training Accuracy: 0.9366, Training F1: 0.8127
Validation Loss: 0.7211, Validation Dice: 0.2789, Validation Focals: 0.1815, Validation BCE: 0.6852, Validation Accuracy: 0.9361, Validation F1: 0.7599
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6890, Training Dice: 0.3110, Training Focals: 0.1579, Training BCE: 0.6488, Training Accuracy: 0.9698, Training F1: 0.8890
Validation Loss: 0.7172, Validation Dice: 0.2828, Validation Focals: 0.1677, Validation BCE: 0.6657, Validation Accuracy: 0.9563, Validation F1: 0.8190
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: AdamW, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6890, Training Dice: 0.3110, Training Focals: 0.1580, Training BCE: 0.6489, Training Accuracy: 0.9695, Training F1: 0.8883
Validation Loss: 0.7167, Validation Dice: 0.2833, Validation Focals: 0.1647, Validation BCE: 0.6623, Validation Accuracy: 0.9625, Validation F1: 0.8406
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adamax, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6914, Training Dice: 0.3086, Training Focals: 0.1659, Training BCE: 0.6592, Training Accuracy: 0.9553, Training F1: 0.8515
Validation Loss: 0.7164, Validation Dice: 0.2836, Validation Focals: 0.1740, Validation BCE: 0.6741, Validation Accuracy: 0.9482, Validation F1: 0.7995
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: ASGD, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7610, Training Dice: 0.2390, Training Focals: 0.3773, Training BCE: 0.9472, Training Accuracy: 0.3605, Training F1: 0.2106
Validation Loss: 0.7775, Validation Dice: 0.2225, Validation Focals: 0.3717, Validation BCE: 0.9441, Validation Accuracy: 0.3773, Validation F1: 0.1992
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: NAdam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6892, Training Dice: 0.3108, Training Focals: 0.1571, Training BCE: 0.6479, Training Accuracy: 0.9727, Training F1: 0.8989
Validation Loss: 0.7147, Validation Dice: 0.2853, Validation Focals: 0.1738, Validation BCE: 0.6725, Validation Accuracy: 0.9468, Validation F1: 0.7939
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: RAdam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6957, Training Dice: 0.3043, Training Focals: 0.1845, Training BCE: 0.6820, Training Accuracy: 0.9200, Training F1: 0.8017
Validation Loss: 0.7230, Validation Dice: 0.2770, Validation Focals: 0.1851, Validation BCE: 0.6897, Validation Accuracy: 0.9245, Validation F1: 0.7259
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: RMSprop, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6896, Training Dice: 0.3104, Training Focals: 0.1612, Training BCE: 0.6527, Training Accuracy: 0.9614, Training F1: 0.8617
Validation Loss: 0.7187, Validation Dice: 0.2813, Validation Focals: 0.1670, Validation BCE: 0.6655, Validation Accuracy: 0.9594, Validation F1: 0.8282
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Rprop, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6879, Training Dice: 0.3121, Training Focals: 0.1551, Training BCE: 0.6446, Training Accuracy: 0.9732, Training F1: 0.8992
Validation Loss: 0.7215, Validation Dice: 0.2785, Validation Focals: 0.1642, Validation BCE: 0.6625, Validation Accuracy: 0.9550, Validation F1: 0.8001
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: SGD, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.7569, Training Dice: 0.2431, Training Focals: 0.3148, Training BCE: 0.8753, Training Accuracy: 0.6222, Training F1: 0.2663
Validation Loss: 0.7694, Validation Dice: 0.2306, Validation Focals: 0.3396, Validation BCE: 0.9040, Validation Accuracy: 0.5215, Validation F1: 0.2561plot_selected(optimizer_results, ['Adam', 'AdamW', 'Rprop'])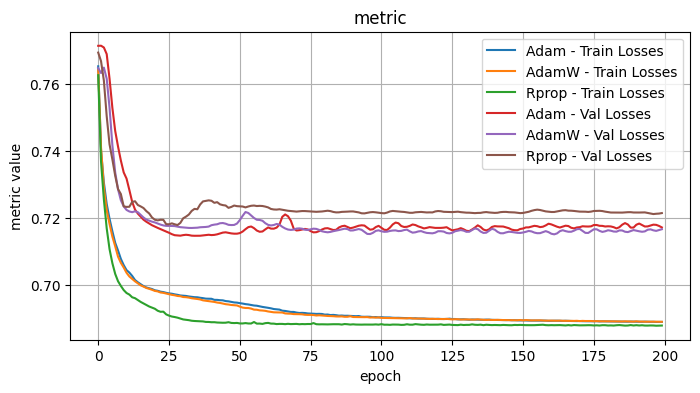
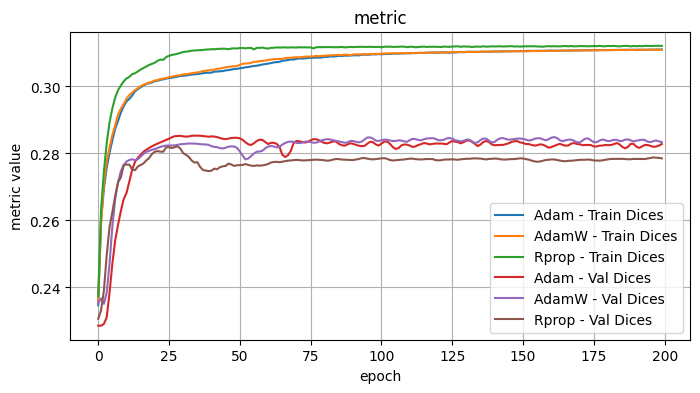
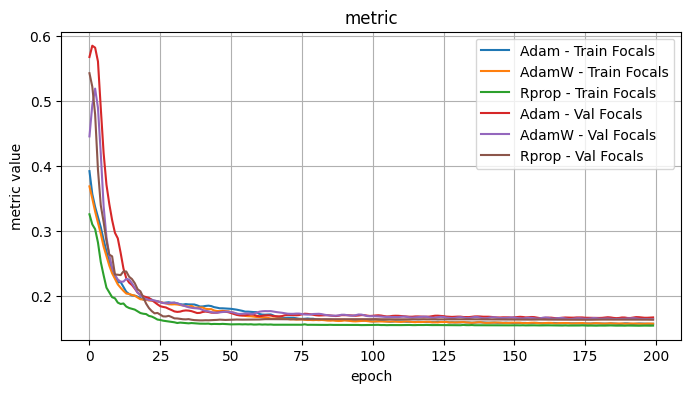
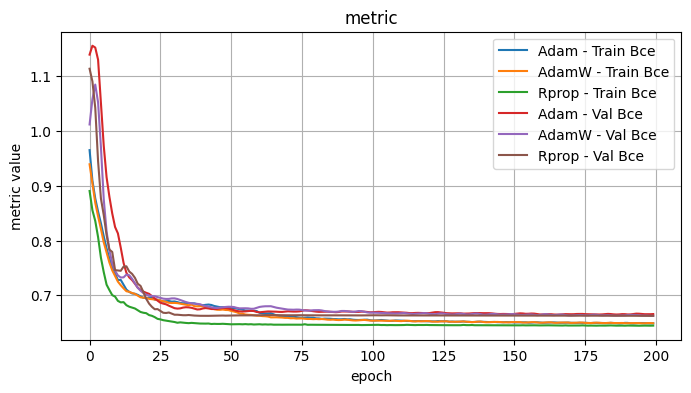
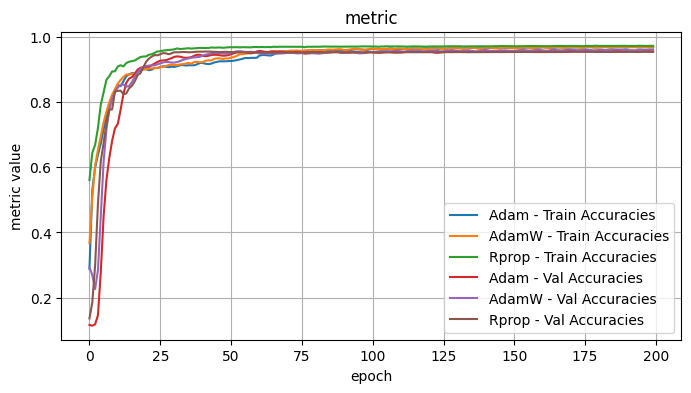
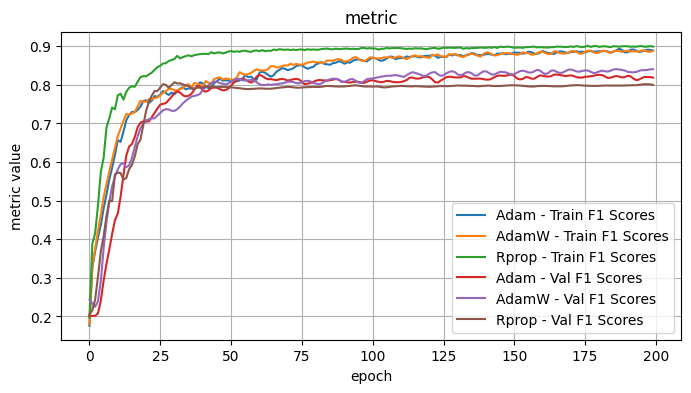
3.1 Conclusions - Optimizers
I tested the optimizers with the following fixed choices: Model Architecture: UPerNet, Model encoder / weights: mit_b5 / imagenet, LR: 1e-4, Loss Function: Dice Loss
Observe: - Adadelta, ASGD, SGD - the validation curves showed minimal improvement and were noisy. I would suspect further hyperparameter tweaks would be necessary for these optimizers. - Adam, AdamW - Quite comparable curves and performance, with the edge to Adam.
The best optimizers appeared to be Adam and Rprop.
4 Loss functions
# @title
loss_results = {}
loss_functions = ['FocalLoss', 'DiceLoss', 'SoftBCEWithLogitsLoss', 'IOULoss', 'TverskyLoss', 'LovaszLoss', 'CombinedLoss']
for loss_function in loss_functions:
model, train_losses, train_dices, train_focals, train_bce, train_accuracies, train_f1_scores, val_losses, val_dices, val_focals, val_bce, val_accuracies, val_f1_scores = train_model(
num_epochs=200,
patience=0,
model_name="UPerNet",
encoder_name="mit_b5",
encoder_weights="imagenet",
optimizer_type="Adam",
lr=1e-4,
loss_function_type=loss_function
)
loss_results[loss_function] = {
'train_losses': train_losses,
'train_dices': train_dices,
'train_focals': train_focals,
'train_bce': train_bce,
'train_accuracies': train_accuracies,
'train_f1_scores': train_f1_scores,
'val_losses': val_losses,
'val_dices': val_dices,
'val_focals': val_focals,
'val_bce': val_bce,
'val_accuracies': val_accuracies,
'val_f1_scores': val_f1_scores
}--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: FocalLoss
Finished Training
Training Loss: 0.1557, Training Dice: 0.3063, Training Focals: 0.1557, Training BCE: 0.6476, Training Accuracy: 0.9821, Training F1: 0.9281
Validation Loss: 0.1664, Validation Dice: 0.2740, Validation Focals: 0.1664, Validation BCE: 0.6675, Validation Accuracy: 0.9537, Validation F1: 0.7967
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: DiceLoss
Finished Training
Training Loss: 0.6890, Training Dice: 0.3110, Training Focals: 0.1580, Training BCE: 0.6489, Training Accuracy: 0.9693, Training F1: 0.8877
Validation Loss: 0.7131, Validation Dice: 0.2869, Validation Focals: 0.1667, Validation BCE: 0.6632, Validation Accuracy: 0.9591, Validation F1: 0.8391
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: SoftBCEWithLogitsLoss
Finished Training
Training Loss: 0.6483, Training Dice: 0.3076, Training Focals: 0.1564, Training BCE: 0.6483, Training Accuracy: 0.9808, Training F1: 0.9240
Validation Loss: 0.6630, Validation Dice: 0.2801, Validation Focals: 0.1642, Validation BCE: 0.6630, Validation Accuracy: 0.9662, Validation F1: 0.8541
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: IOULoss
Finished Training
Training Loss: 0.8159, Training Dice: 0.3110, Training Focals: 0.1580, Training BCE: 0.6489, Training Accuracy: 0.9695, Training F1: 0.8895
Validation Loss: 0.8328, Validation Dice: 0.2865, Validation Focals: 0.1662, Validation BCE: 0.6628, Validation Accuracy: 0.9602, Validation F1: 0.8390
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: TverskyLoss
Finished Training
Training Loss: 0.6889, Training Dice: 0.3111, Training Focals: 0.1579, Training BCE: 0.6486, Training Accuracy: 0.9691, Training F1: 0.8873
Validation Loss: 0.7138, Validation Dice: 0.2862, Validation Focals: 0.1651, Validation BCE: 0.6621, Validation Accuracy: 0.9642, Validation F1: 0.8542
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: LovaszLoss
Finished Training
Training Loss: 0.8843, Training Dice: 0.3061, Training Focals: 0.1557, Training BCE: 0.6477, Training Accuracy: 0.9838, Training F1: 0.9344
Validation Loss: 0.9390, Validation Dice: 0.2775, Validation Focals: 0.1616, Validation BCE: 0.6604, Validation Accuracy: 0.9706, Validation F1: 0.8613
--------------------------------------------------
Training with Model Architecture: UPerNet, Encoder: mit_b5, Weight: imagenet, Optimizer: Adam, LR: 0.0001, Loss Function: CombinedLoss
Finished Training
Training Loss: 1.8152, Training Dice: 0.3108, Training Focals: 0.1560, Training BCE: 0.6466, Training Accuracy: 0.9757, Training F1: 0.9071
Validation Loss: 1.9167, Validation Dice: 0.2844, Validation Focals: 0.1626, Validation BCE: 0.6594, Validation Accuracy: 0.9678, Validation F1: 0.8643plot_selected(loss_results, ['FocalLoss', 'DiceLoss', 'SoftBCEWithLogitsLoss', 'CombinedLoss'], plot_loss=False)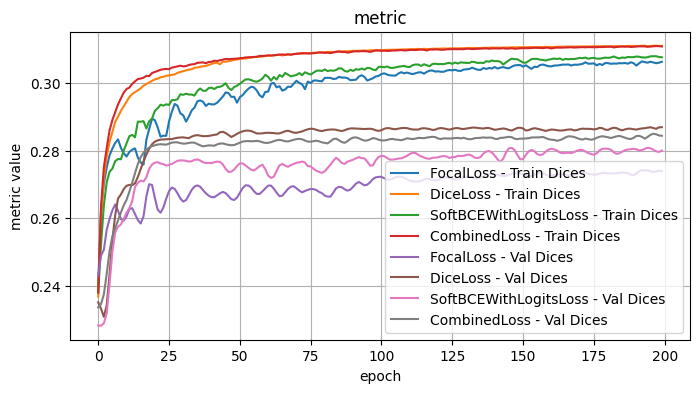
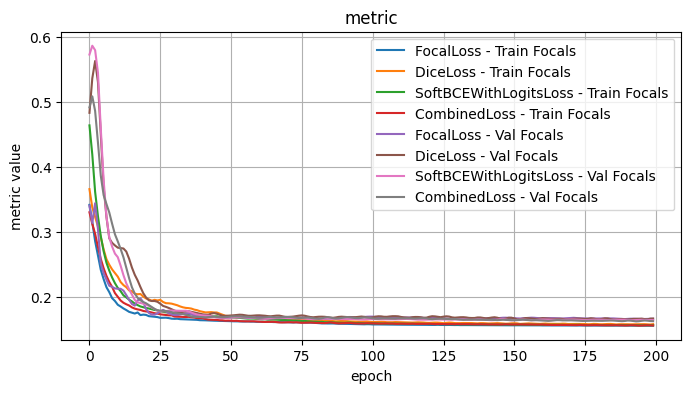
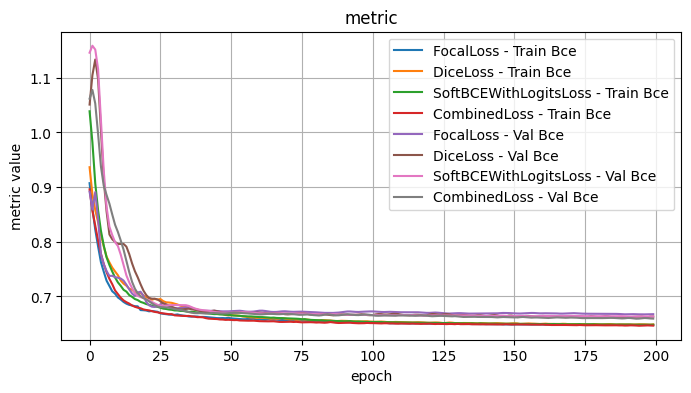
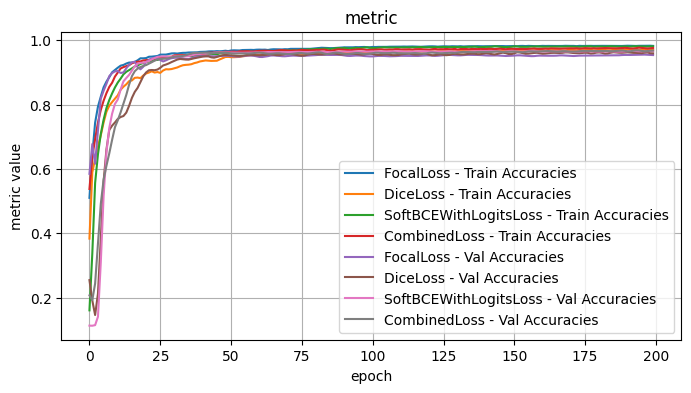
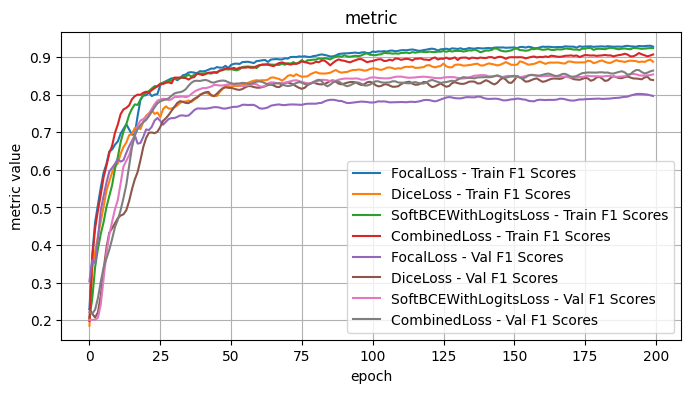
4.1 Conclusions - Loss Functions
I tested the model architecture with the following fixed choices: Model encoder / weights: mit_b5 / imagenet, Model Architecture: UPerNet, Optimizer: Adam, LR: 1e-4, Loss Function: Dice Loss
The loss functions generally yielded similar results, without much differentiaton. This may in part be due to the fact that the other optimizations have made it hard to distinguish differences at this scale.
As it stands, I think that the combined loss function is a very reasonable choice, given that its successful usage in image segmentation tasks.
5 Results:
- Model Encoder and Encoder Weights: mit_b5 / imagenet
- Model Architecture: UPerNet
- Optimizer: Adam
- Learning Rate: 1e-4
- Loss Function: Combined Loss (Focal + LogDice)